

In the last two years, artificial intelligence programs have reached a surprising level of linguistic fluency. The biggest and best of these are all based on an architecture invented in 2017 called the transformer. It serves as a kind of blueprint for the programs to follow, in the form of a list of equations.
But beyond this bare mathematical outline, we don’t really know what transformers are doing with the words they process. The popular understanding is that they can somehow pay attention to multiple words at once, allowing for an immediate “big picture” analysis, but how exactly this works—or if it’s even an accurate way of understanding transformers—is unclear. We know the ingredients, but not the recipe.
Now, two studies by researchers from the company Anthropic have started to figure out, fundamentally, what transformers are doing when they process and generate text. In their first paper, released in December 2021, the authors look at simplified versions of the architecture and fully explain how they function. “They give a very nice characterization of how they work in the very simple case,” said Yonatan Belinkov of the Technion in Haifa, Israel. “I’m very positive about this work. It’s interesting, promising, kind of unique and novel.”
The authors also show that simple transformers go from learning basic language patterns to picking up a general ability for language processing. “You see that there is this leap in competence,” said Martin Wattenberg of Harvard University. The authors “are starting to decipher the recipe.”
In their second paper, posted March 8, 2022, the researchers show that the same components responsible for this ability are also at play in the most complex transformers. While the mathematics of those models remains largely impenetrable, the results offer an inroad to understanding. “The thing they found in toy models translates to the larger models,” said Connor Leahy of the company Conjecture and the research group EleutherAI.
It’s doing something that looks a little more like abstract reasoning.
The difficulty in understanding transformers lies in their abstraction. Whereas a conventional program follows an understandable process, like outputting the word “grass” whenever it sees the word “green,” a transformer converts the word “green” into numbers and then multiplies them by certain values. These values (also called parameters) dictate what the next word will be. They get fine-tuned during a process called training, where the model learns how to produce the best outputs, but it’s unclear what the model is learning.
Most machine learning programs package their math into modular ingredients called neurons. Transformers incorporate an additional type of ingredient, called an attention head, with sets of heads arranged in layers (as are neurons). But heads perform distinct operations from neurons. The heads are generally understood as allowing a program to remember multiple words of input, but that interpretation is far from certain.
“The attention mechanism works, clearly. It’s getting good results,” said Wattenberg. “The question is: What is it doing? My guess is it’s doing a whole lot of stuff that we don’t know.”
To better understand how transformers work, the Anthropic researchers simplified the architecture, stripping out all the neuron layers and all but one or two layers of attention heads. This let them spot a link between transformers and even simpler models that they fully understood.
Consider the simplest possible kind of language model, called a bigram model, which reproduces basic language patterns. For example, while being trained on a large body of text, a bigram model will note what word follows the word “green” most often (such as “grass”) and memorize it. Then, when generating text, it will reproduce the same pattern. By memorizing an associated follow-up word for every input word, it gains a very basic knowledge of language.
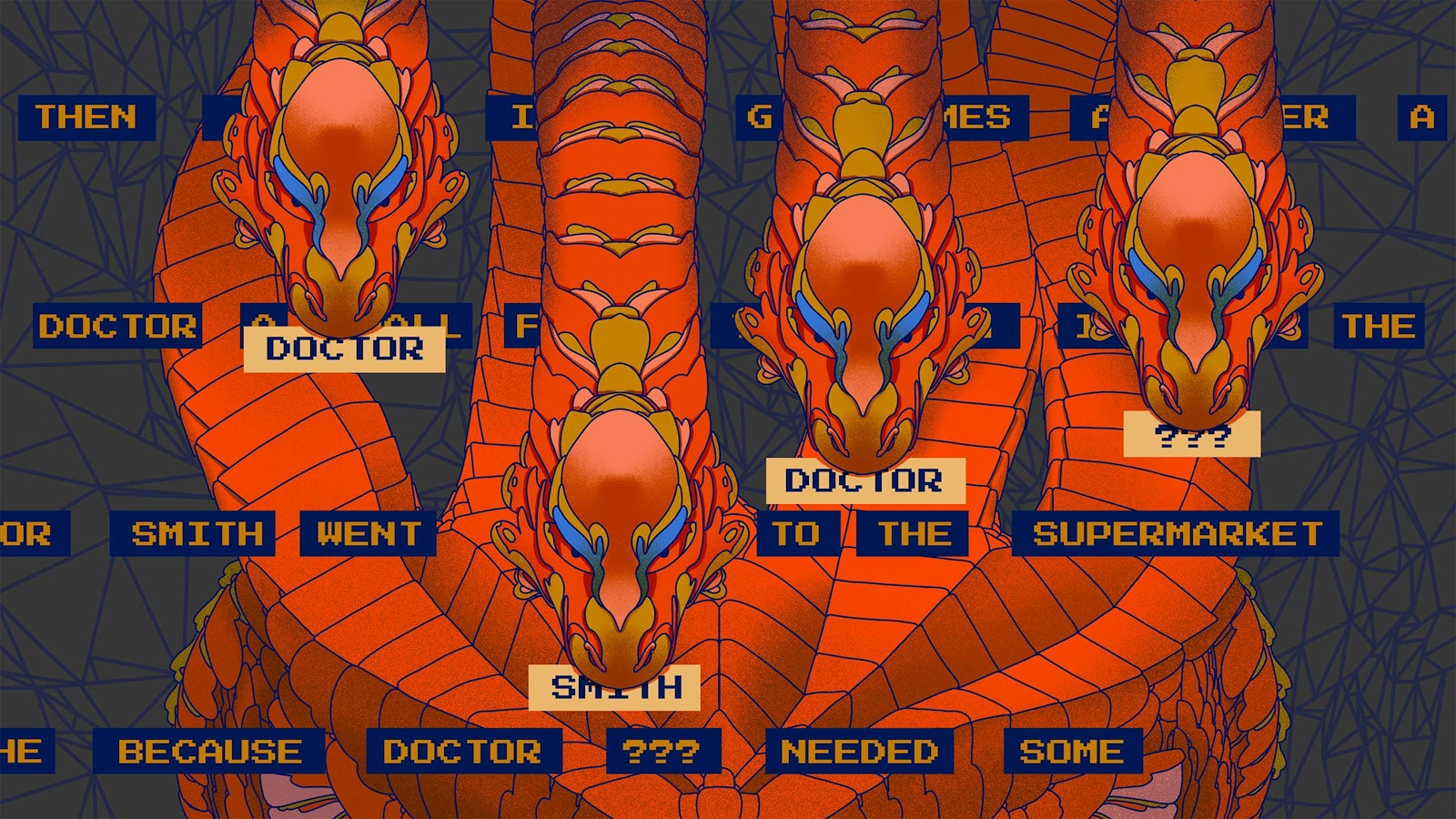
The researchers showed that a transformer model with one layer of attention heads does something similar: It reproduces what it memorizes. Suppose you give it a specific input, like “Doctor Smith went to the store because Doctor …” This input is called the prompt, or context. For us, the next word is obvious—Smith.
An attention head in a trained one-layer model can make this prediction in two steps. First, it looks at the final word in the context (Doctor) and searches for a specific word in the context that it has learned (during training) to associate with the final word. Then, for any word that it finds, it looks up another word that it has learned to associate with the found word, as in the bigram model. (This can be the same word.) It then moves this associated word to the model’s output.
For this example, the researchers show that based on the final word, “Doctor,” the head knows from its training to search for a word that is a common name. On finding the name “Smith” earlier in the sentence, the head looks at what it’s learned to associate with “Smith” and moves that word to the output. (In this case, the model has learned to associate the same word “Smith” with the found word “Smith.”) The net effect of the overall process is that the model copies the word “Smith” from the context to the output.

“Here, we can actually understand the role of attention,” said Chris Olah of Anthropic, one of the co-authors.
But memorization can only take a model so far. Consider what happens when the name Smith is changed to a made-up name, such as “Gigamuru.” For us, the sentence completion remains obvious—Gigamuru—but the model will not have seen the made-up word during training. Therefore, it cannot have memorized any relationships between it and other words, and will not generate it.
The Anthropic team found that when they studied a more complex model—one with two layers of attention heads—a solution emerged. It relies on an ability unique to attention heads: They can move information not only to the output, but also to other places in the context. Using this ability, a head in the first layer learns to annotate each word in the context with information about the word that preceded it. The second head can then search for the word that was preceded by the word “Doctor” (in this case, “Gigamuru”) and, like a head in a one-layer model, move it to the output. The researchers call an attention head in a latter layer that collaborates with a head in an earlier layer an induction head. It does more than memorization.
“It’s doing something that looks a little more like abstract reasoning, or implementing an algorithm,” said Nelson Elhage of Anthropic, also a co-author. “This has a little bit of that flavor.”
Induction heads let a two-layer model do more, but their relevance wasn’t clear for full-scale transformers, which have hundreds of attention heads collaborating together. In their second paper, the researchers found that the findings carry over: Induction heads appear to strongly contribute to some of the remarkable behaviors of the most complex, many-layer architectures.
Among these behaviors is the ability to do arithmetic, remarkable because models are only trained to complete text. For example, if given the repetitive prompt: “Q: What is 48 plus 76? A: 124, Q: What is 48 plus 76? A:” a full-scale model will get the right answer. And after being given enough non-repetitive examples, it will be able to correctly answer arithmetic questions it has never seen. This phenomenon of apparently learning novel abilities from the context is called in-context learning.
The phenomenon was puzzling because learning from the context should not be possible. That’s because the parameters that dictate a model’s performance are adjusted only during training, and not when the model is processing an input context.
Induction heads resolve at least part of the puzzle. They explain how simple, repetitious forms of in-context learning are possible, providing just what’s needed: an ability to copy novel words (like “Gigamuru” or “124”) that a model has not been trained to work with.
“The induction head is more likely to do whatever the pattern is, even if it’s kind of weird or new,” said Catherine Olsson of Anthropic, another co-author.
The researchers went further, identifying induction heads in many-layer models and showing that they are involved in the more novel forms of in-context learning, like learning to translate between languages.
“It’s not purporting to explain the entire mechanism,” said Jacob Hilton of OpenAI. “Only that the induction heads seem to be involved.”
The results give us a foothold into understanding transformers. Not only are they acquiring knowledge, they’re also learning ways to process things they have not learned at all. Perhaps by knowing that they do this, we can be a little less surprised that they surprise us.
Lead image: Avalon Nuovo for Quanta Magazine
This article was originally published on the Quanta Abstractions blog.