On a warm day in April 2013, I was sitting in a friend’s kitchen in Paris, trying to engineer serendipity. I was trying to get my computer to write music on its own. I wanted to be able to turn it on and have it spit out not just any goofy little algorithmic tune but beautiful, compelling, mysterious music; something I’d be proud to have written myself. The kitchen window was open, and as I listened to the sounds of children playing in the courtyard below, I thought about how the melodies of their voices made serendipitous counterpoint with the songs of nearby birds and the intermittent drone of traffic on the rue d’Alésia.
In response to these daydreams, I was making a few tweaks to my software—a chaotic, seat-of-the-pants affair that betrayed my intuitive, self-taught approach to programming—when I saw that Bill Seaman had just uploaded a new batch of audio files to our shared Dropbox folder. I had been collaborating with Bill, a media artist, on various aspects of computational creativity over the past few years. I loaded Bill’s folder of sound files along with some of my own into the software and set it rolling. This is what came back to me:
I was thrilled and astonished. It was exactly what I was hoping for: The computer had created alluring music—music I wanted to listen to!—from a completely unexpected manipulation of the sonic information I had given it. The music was at once futuristic and nostalgic, slightly melancholy, and quite subtle: Even the digital noise samples it used—basically sonic detritus—seemed sensitively integrated. It gave me the distinct, slightly disorienting, feeling that the computer was showing me something vital and profound about an art form that I had practiced for over 20 years. This fragile, beautiful music had qualities that were utterly new to me, and I wondered what else I could learn from the computer about musical possibility.
When I returned to the United States, I met Bill in his studio in a repurposed tobacco warehouse on the campus of Duke University, where we are both on the faculty. I showed him the software processes that produced the music that excited me. We immediately began brainstorming workflows that imagined the computer as a full-fledged collaborator. We wanted to invent a silicon-based life form to help make music that mere carbon-based life forms could never imagine on their own. Our rationale was that the computer could quickly navigate vast amounts of sonic information and return results that would have never occurred to us. If we could increase the probability that the computer would deliver compelling and unusual results, we would have essentially built the ideal artistic collaborator: miraculously inventive, tireless, and egoless.
Bill and I had another—you might say lofty—goal. We wanted to spotlight the creative process in both humans and computers. We wanted to show how it was similar, how it was different, and how the two processes together could expand the scope of artistic expression.
As Bill and I saw it, human creativity can be defined as making connections—governed by unpredictable, subjective forces—between seemingly unrelated bits of information. Music is particularly well suited to serve as a model for the creative process. Human composers have multiple components of information—melody, harmony, rhythm—at their fingertips. But composers don’t normally don’t write the melodies, harmonies, and rhythms of a piece sequentially. These elements tend to implicate each other and emerge together from the composer’s imagination. Bill and I wanted to emulate this organic emergence of interrelated elements in the computer.
In fact, we wanted to show that computers can be profoundly creative, can do things that humans can’t. For most of human history, our creative intuitions have been inextricably linked with memory: What we call inspiration is often a remix of ideas that we have encountered in the past, in the works of others. Computational processes make it possible to disentangle memory from the creative impulse by generating results that do not rely on what Ray Kurzweil calls the human brain’s 300 million “pattern processors.” All human knowledge, according to Kurzweil, is reducible to patterns of information that are stored, through learning and experience, in the neocortex.
Imagine asking a human composer to write a melody using only the white notes of the piano; then give a computer the same instructions. The computer wouldn’t have spent a lifetime being conditioned by voluntary and involuntary musical consumption, nor would it have the kind of muscle memory that years of piano lessons produce in a composer. Furthermore, computers are unburdened by questions of taste and style, and don’t tend to make wrongheaded assumptions that might bypass innovation. There’s nothing inherently wrong, of course, with the remix model of creativity. Observing the influence of one artist on another affirms the communal aspect of artistic expression, the fact that artists don’t work in a vacuum. But there’s also no reason that human creativity should be limited by human physiology.
After three years of discussions and experiments, Bill and I produced an album of electronic music called s_traits. It came out on this past November and we were thrilled when The New York Times named it one of the “Top Music Recordings of 2014,” calling it “emotive and eerily beautiful.” We were certainly glad to take the credit, but it didn’t belong entirely to us. Although we created the computer system that produced the album, we were consistently startled at the musical intelligence it seemed to possess.
We began by amassing an enormous database of more than 110 hours of audio, the trove of information that our software system would eventually use to form its own compositions. The database sources included fragments of discarded pieces; field recordings; recordings of our respective early works; acoustic instrumental samples, including recordings Bill and I made on a beautiful Steinway at Duke; electronic drones; soundtracks from obscure, old documentaries; and digital noise generated by opening PDFs as raw data in a sound editor. One of the discarded pieces was the early electronic version of my percussion duo Straits (2010), a work inspired by the Kenneth Koch poem of the same name, which now exists only as an acoustic piece. I Dropboxed the electronic track from Straits over to Bill, who chopped it up into tiny slivers of sound.
At first we put whatever we wanted into the database. After a while, however, we found that we were evolving an unspoken set of criteria for what stayed and what went. We’d periodically survey the database contents and delete anything that struck us as out of place. Here are a few examples of sound files that survived the culling:
These sound files made the cut because they have a mysterious allure. They contain kernels of melodic or rhythmic information and are spacious enough to be integrated with other samples. I should also mention that these samples were themselves probably generated from other sound files in the database. We added a degree of self-referentiality to the database by generating new samples from existing ones.
We knew that whatever information we put into the database would have a real but unpredictable effect on the music generated from it. Every sample could potentially be chosen by the system at any moment, but it was impossible to know when that might occur. By organizing the samples into categories of roughly equal size—drones, melodies, chords, rhythms, noise, and so forth—we would be able to maximize the variety of system’s output. After about three years of hoarding audio, we were finally satisfied that the database contained the right quantity and mix of samples. We could start thinking seriously about what kind of software processes were needed to extract the full, crazy potential from our expansive sound world.
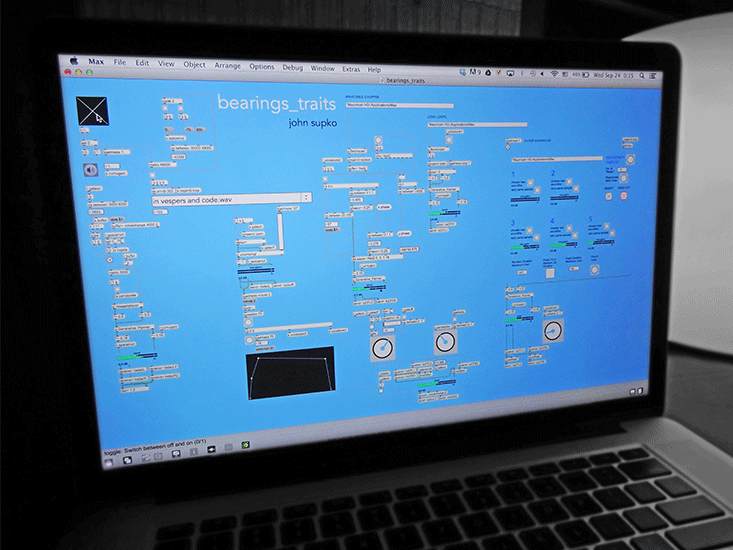
So just how did we get our system—which we now call bearings_traits—to compose music instead of simply outputting random sounds? The easiest way for me to describe the design-thinking behind bearings_traits is to take a brief detour into the world of frogs.
We wanted to invent a silicon-based life form to help make music that mere carbon-based life forms could never imagine on their own.
One day when Bill and I were discussing some aspect of our project, he mentioned a 1959 paper co-written by the American cognitive scientist Jerome Lettvin and the Chilean biologist and cyberneticist Humberto Maturana titled “What the Frog’s Eye Tells the Frog’s Brain.” The part of the article that most interested me described how the complex phenomenon of sight arises from the concurrence of four simple operators, namely, the fibers of the frog’s optic nerve that detect the contrast, convexity, movement, and dimming of an object in its field of vision. In isolation, the information each bundle of fibers delivers to the frog’s brain isn’t terribly exciting. But firing in concert, they produce a composite image of the frog’s surroundings that allows it to hop and swim and hunt.
This gave me the idea to build bearings_traits as a network of many tiny software functions, arranged like the bundles of amphibian optic fibers I read about. I was fascinated that something as miraculous as sight could arise from connecting simple binary processes such as light/dark detection. Of course, car engines also work this way, if less mysteriously: spark plugs fire, pistons move, and you get to where you’re going. Invigorated by this biological detour, my thinking about bearings_traits veered toward mechanical analogies. I thought of the individual software processes making up bearings_traits as little machines that each perform one simple task contributing to the larger, more complex goal of creating computer-generated music.

Perhaps the most basic example of one of these machines is the kind that simply determines the duration of a sound file. Before bearings_traits can do anything compelling with a sample, it has to know how long it is. Some of the machines operate on only a portion of a given sample, randomly selecting the start- and endpoints of the portion it will play. If a sound file is only 22 seconds long, for example, we wouldn’t want the system to try to play anything past 22 seconds because there’d be nothing to play. Once bearings_traits knows the sizes of the files it’s dealing with, it can pass that information to other machines that do more interesting things, such as creating strange rhythmic loops from the chosen files based on precisely calculated durations.
During the development phase of bearings_traits, I would typically code some aspect of the system using the popular visual programming language Max/MSP and show it to Bill. For example, perhaps we were working on a way for the system to transition smoothly from one rhythmic pattern to another. We would load in a few sound files and listen to what the computer was doing with them. Then we’d try to figure out how to improve it—maybe the transition functionality was too fast or too slow—or to elaborate it further. To give you an idea of what these brainstorming sessions were like, I’ll input those sound files I showed you a moment ago into a very early version of the system. Let’s see what happens.
At this point, Bill would come up with a million new ideas, which he’d rattle off, rapid-fire, as I hunched over my laptop trying to turn the damn thing off: Maybe the system could detect the pitch information of what it was writing and then call up banks of harmonizing drones or compose new contrapuntal melodies? Maybe the system could record itself and then pass those recordings back into the system, automating the generative process? I’d get confused and overwhelmed and wild-eyed. Then I’d go home and try desperately to incorporate some of Bill’s brilliant suggestions into the system. Afterward we’d meet again and repeat the entire exercise.
When the software began at long last to spit out what seemed to us like “first draft” compositions—meaning that we perceived both a structural integrity to the music as well as the potential for further development—we started to intervene as the computer’s collaborators in order to bring the “drafts” to completion. Our approach was to keep the computer’s staggering inventiveness but to refine it in ways only a human (at least for the moment) can. For instance, if I heard something—a melody, a chord progression—that had an emotional attraction for me, I would draw attention to it in the mix, repeating it and developing it further if necessary. If there was potential for a dramatic moment of attack or climax, I’d try to bring it out. Bill made similar interventions. All 26 tracks of s_traits were the results of this triangular collaborative process. Here’s one of them, titled “flung overboard as poetic justice”:
To foster emergence, and fresh connections, one of the most versatile little machines that we created in bearings_traits is something we call a “generative looper.” We call this machine generative because it literally generates its own rhythmic profile in real time. Every time bearings_traits triggers the looper it plays a different segment of the sound file loaded into it. This ensures that the looper will never exactly repeat itself. The duration of the chosen segments can be fixed or variable. If the looper is set to find a new segment as soon as it finishes playing the previous segment, a glitchy rhythm can be prolonged indefinitely. Depending on the nature and length of the sound file, and the average length of the chosen segments, the resulting effects can range from subtle undulations to rather dramatic convulsions.
Several copies of the generative looper can be bundled into a larger device we call an engine. In one such engine, the output of up to five loopers operating simultaneously on five different samples can be superimposed, instantly creating complex, polyphonic textures.
In contrast to the generative looper engine’s continuous, multi-layered textures, another engine comprised of machines that each look for a tiny amount of sound in the database—let’s call this one the fragment engine—can play up to five different fragments in alternation in order to create unpredictable rhythmic patterns. The number of sound files used to create a pattern, the duration of the fragments extracted from each file, the playback direction (backward or forward) of each fragment, and the order in which each fragment is played are all subject to discrete decisions made by the system. Bearings_traits can also decide (or be set) to make patterns in which all sound fragments have the same duration, which would create a more or less regular rhythmic feel, or to make a random decision about how long each fragment will be, creating much stranger, asymmetrical grooves.
Bearings_traits has two basic methods for integrating the audio produced by its various components into a “final” mix. One method amounts to the computer controlling a mixing board, deciding which faders to boost and which to attenuate. In this way, discrete channels of audio from one engine can be replaced by those of another engine. Crossfades—the simultaneous fade-in of one sound as another fades-out—are also possible at varying speeds, from imperceptibly gradual to almost instantaneous. An entire subset of machines is dedicated to managing these mixing board functionalities. These machines detect when sound is coming through a channel they control and can decide to fade it in or out.
Not only can computers process more information than humans can, they are also unburdened by questions of taste and style.
The other method amounts to bearings_traits remixing the music it composes in real time. Bill wanted to give the system the ability to record itself and then modify the recording in various ways, adding the modified version back into music it was making. One way bearings_traits can modify its recordings is by changing the playback speed. Not only does this change the pitch of the material in the recording, it also has the potential to create a static, drone-like effect if the playback speed is very slow, or a burst of manic sonic energy, if the recording is speeded up significantly. Bearings_traits can also play back portions of its self-recordings at regular or irregular time intervals, creating idiosyncratic interjections in the musical texture. At any moment, the speed of each interjection can be modified. By linking these two simple functionalities—playback time intervals and playback speed—a much more dynamic result emerges. The music doesn’t simply repeat mechanically; its patterns feature strange little anomalies, such as fragmentations and pitch changes, which create interest.
When we listen to the results of these operations on the sound material that we load into bearings_traits, it’s tempting for Bill and me to believe that we’ve gotten closer to the dream of engineering serendipity, or at least increasing its frequency. To see what we mean, here is a new “draft” composition generated especially for Nautilus by the current version of bearings_traits. I’ve been demonstrating the capabilities of only components of the system. This short recording will give you an idea of what bearings_traits can do when all the component machines are linked together. You’ll also probably hear why we consider these “drafts” ripe for further development by human musicians. Our compositional process always begins this way, by turning on bearings_traits and following the unpredictable results to places we couldn’t have imagined before.
The spoken words you hear are fragments of a long text Bill wrote for s_traits as a response to the poem “Straits” by Kenneth Koch, which had inspired my earlier percussion duo. At the beginning of each new composition it generates, bearings_traits chooses one text fragment recording, read by Bill, to serve as a title as well as a suggestive prompt to color the listener’s experience of the music.
Most of the generative processes I’ve been describing use some form of repetition. The dynamic handling of repetition is a major aspect of the design of bearings_traits. In music, as in most forms of human expression, repetition is used to distinguish what is important from what is less so; it’s how meaning is elaborated by the composer and perceived by the listener. In a Mozart piano sonata, the thematic building blocks of the music are identifiable because they are usually the most prominently repeated elements in the piece. That’s no mystery. It’s exactly what you’d expect. What is mysterious, however, is the proportion of repetition to variation of the material, the thought processes that lead a composer to diverge from a repeated pattern in order to introduce a new detail. Indeed, that new detail might then itself become structurally important to the music by dint of repetition.
Bearings_traits plays with the proportions of repetition and variation in the music that it generates, but does so in quirky, improvisational ways. Perhaps more than anything else, this detail of the system demonstrates that the work Bill and I are doing privileges the artistic result over any kind of scientific or technological standard. In attempting to harness computational creativity, we never nursed the hope of one day replacing ourselves as composers. Once we started being delighted and astonished by the system’s output, we could stop pretending to be computer scientists and concentrate on the business of making weird music.

Bill and I love the compositions bearings_traits is able to concoct. It’s often oddly beautiful, inside-out, upside-down music that inspires us to contribute surprising details of our own devising. The creativity of the system enables us to use our own creativity differently. And when we don’t like what bearings_traits comes up with, we simply throw it out and ask for more, with no hard feelings.
Bill and I always planned to refine the system’s compositions ourselves. At present, bearings_traits simply can’t observe what it’s doing and make value judgments. It can’t listen and say, “That’s amazing! I want to do more with that!” We reserved that role for ourselves because our ultimate goal was to make striking, original music for humans to listen to. Besides, adapting our human creativity to the computer’s strange musical material was an education in itself.
Our strong feelings about human intervention in the computer’s work shouldn’t suggest that we’re uninterested in continuing to develop the capabilities of bearings_traits. On the contrary, there’s an endless amount of exciting work still to be done. For my part, I aspire to make works that will continue to evolve and reinvent themselves long after I’m gone. To a certain extent, Bill and I have already accomplished this goal. We can install bearings_traits in a room and turn it on indefinitely, confident that it won’t ever come close to repeating itself. But we can go further than simply guaranteeing constant, endless invention. Giving the system a kind of self-awareness is an obvious next step.
In theory, every decision bearings_traits makes can be codified, recorded, and analyzed. Examples of these decisions might include: the sound files chosen (and which parts of them), the frequencies or pitches the sound files contain, the number of machines playing concurrently, and the resulting harmonies of the musical textures. From this information it would be relatively easy to give bearings_traits the ability to develop something akin to its own taste, assigning values to its past behaviors and allowing it either to increase or decrease—arbitrarily at first, then eventually with the weight of historical precedent—the recurrence of these behaviors in future compositions.
Ultimately, the music Bill and I wrote with bearings_traits showed us that computation could indeed complement human creativity with thrilling results. In the future, humans will continue to be the arbiters of their artworks, but the option to integrate computer-generated materials derived from raw information—a series of chords, images, choreographic movements—will only serve to enrich artistic practice. Moreover, technology will increase its potential to uncover unexpected, electrifying connections between seemingly disparate fields of information. And far from dehumanizing art, the development of technological processes to expand the scope of human expression follows a deeply human trajectory. Works of art developed with the aid of such technology will, in turn, ever more closely reflect the frenetic, promiscuous, voracious human minds that create them.
John Supko is the Hunt Family Assistant Professor of Music at Duke University, where he and Bill Seaman co-direct The Emergence Lab in the Media Arts + Sciences program. Supko’s music can be heard on the New Amsterdam and Cotton Goods labels.