



The Earth may not be flat, but the web certainly is.
“There is no ‘top’ to the World-Wide Web,” declared a 1992 foundational document from the World Wide Web Consortium—meaning that there is no central server or organizational authority to determine what does or does not get published. It is, like Borges’ famous Library of Babel, theoretically infinite, stitched together with hyperlinks rather than top-down, Dewey Decimal-style categories.1 It is also famously open—built atop a set of publicly available industry standards.
While these features have connected untold millions and created new forms of social organization, they also come at a cost. Material seems to vanish almost as quickly as it is created, disappearing amid broken links or into the constant flow of the social media “stream.” It can be hard to distinguish fact from falsehood. Corporations have stepped into this confusion, organizing our browsing and data in decidedly closed, non-transparent ways. Did it really have to turn out this way?
The web has played such a powerful role in shaping our world that it can sometimes seem like a fait accompli—the inevitable result of progress and enlightened thinking. A deeper look into the historical record, though, reveals a different story: The web in its current state was by no means inevitable. Not only were there competing visions for how a global knowledge network might work, divided along cultural and philosophical lines, but some of those discarded hypotheses are coming back into focus as researchers start to envision the possibilities of a more structured, less volatile web.
By the late 19th century, the modern information age had already begun. The industrialization of the printing press, coupled with the introduction of cheap rag paper, had dramatically altered the economics of publishing. Much of Europe and North America was awash in data. Daily newspapers, cheap magazines, and mass-market novels all emerged during this period, along with a flurry of institutional reports, memos, and all kinds of other printed ephemera.
Meanwhile, new communications technologies like the telegraph and telephone were cropping up. Tram and railway lines were proliferating. An increasingly internationalized postal service sped the flow of data around the globe. By 1900, a global information network had already started to take shape.
The industrial information explosion triggered waves of concern about how to manage all that data. Accomplished librarians like Melvil Dewey (of Decimal System fame), Sir Anthony Panizzi of the British Library, and Charles Cutter of the Boston Athenaeum all began devising new systems to cope with the complexity of their burgeoning collections. In the fast-growing corporate world, company archivists started to develop complex filing systems to accommodate the sudden deluge of typewritten documents.
The dream of organizing the world’s information stemmed not from an authoritarian impulse, but from a deeply utopian one.
Among these efforts, one stood out. In 1893, a young Belgian lawyer named Paul Otlet wrote an essay expressing his concern over the rapid proliferation of books, pamphlets, and periodicals. The problem, he argued, should be “alarming to those who are concerned about quality rather than quantity,” and he worried about how anyone would ever make sense of it all. An ardent bibliophile with an entrepreneurial streak, he began working on a solution with his partner, a fellow lawyer named Henri La Fontaine (who would later go on to join the Belgian Senate and win the Nobel Peace Prize): a “Universal Bibliography” (Repertoire bibliographique universel) that would catalog all the world’s published information and make it freely accessible.
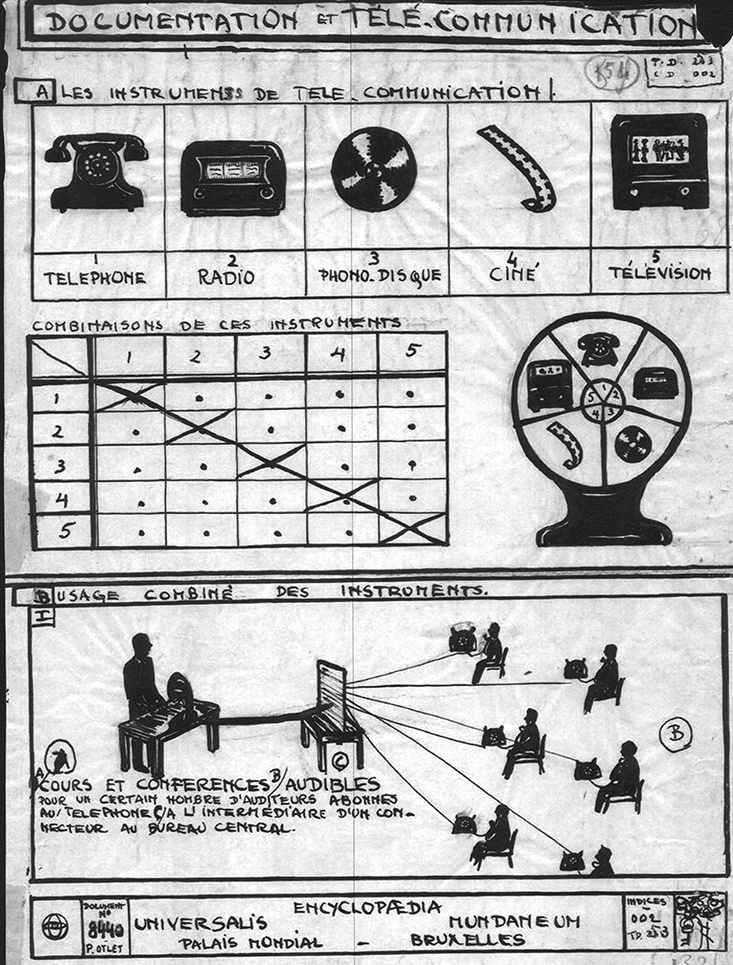
The project won Otlet and La Fontaine a Grand Prize at the Paris World Expo of 1900, and attracted funding from the Belgian government. It would eventually encompass more than 16 million entries ranging from books and periodicals to newspapers, photographs, posters, and audio and video recordings, all painstakingly recorded on individual index cards. Otlet even established an international network of associations and a vast museum called the World Palace (Palais Mondial) or Mundaneum, which at one point occupied more than 100 rooms in a government building.
Otlet’s Mundaneum presented an alternative vision to today’s (nominally) flat and open web by relying on a high degree of bibliographical control. He envisioned a group of trained indexers managing the flow of information in and out of the system, making sure that every incoming piece of data would be properly categorized and synthesized into a coherent body of knowledge. To this end, he and La Fontaine developed a sophisticated cataloging system that they dubbed the Universal Decimal Classification. Using the Dewey Decimal System as its starting point, it started with a few top-level domains (like Philosophy, Social Sciences, and The Arts), which could then be further divided into a theoretically infinite number of sub-topics. This in itself was nothing new, but Otlet introduced an important new twist: a set of so-called “auxiliary tables” that allowed indexers to connect one topic to another by using a combination of numeric codes and familiar marks like the equal sign, plus sign, colon, and quotation marks. So, for example, the code 339.5 (410/44) denoted “Trade relations between the United Kingdom and France,” while 311:[622+669](485) meant “Statistics of mining and metallurgy in Sweden.”
Otlet hoped that this new system would allow for a grand unification of human knowledge, and entirely new forms of information. But neither he nor his Mundaneum survived the ravages of World War II. After invading Brussels, the Nazis destroyed much of his life’s work, removing more than 70 tons worth of material and repurposing the World Palace site for an exhibition of Third Reich art. Otlet died in 1944, and has remained largely forgotten ever since.
Otlet was not alone in his grand vision for a carefully cataloged global network. The English novelist H.G. Wells—a devout socialist, pacifist, and feminist (not to mention ardent promoter of free love)—wrote a series of popular essays that he eventually published in 1938 under the title World Brain.
With Europe standing on the brink of war, he called for a new, deeply ontological approach to managing conflict. “All the distresses and horrors of the present time are fundamentally intellectual,” he wrote. “The world has to pull its mind together.”2 Like Otlet, he saw this undertaking as a central component of a grander, utopian scheme. He envisioned a vast new “encyclopedia” as the distributed brain of a new world order, in which a centralized global information agency would employ an army of technocrats (or “samurai,” as he called them) to curate, classify, and disseminate humanity’s collective knowledge store around the globe.
Other important European thinkers like the German chemist and Nobel laureate Wilhelm Ostwald—who envisioned an Otlet-like universal knowledge repository called “The Bridge” (Die Brücke)—and his protégé Emanuel Goldberg—who invented an early microfilm indexing tool—also explored the possibilities of new, index-driven methods for organizing and distributing the world’s information.
All of these proposals were, first and foremost, managed systems, closely curated collections of knowledge that would have required a high degree of systematic control. And for the most part, they were situated squarely in the public sector, with little role for private enterprise. They emerged in an era of industrialization, when many writers saw great hope in the possibilities of scientific management to improve the human condition; and in a time of war, when many thinkers hoped that a more orderly system would serve as a bulwark against the possibility of international conflict.
In other words, the dream of organizing the world’s information stemmed not from an authoritarian impulse, but from a deeply utopian one. In the United States, though, a very different kind of utopia was being imagined.
Across the Atlantic, an alternative vision of computing was taking shape, driven by a deeply humanistic, individualistic, and American impulse. That vision found its earliest expression in an essay published by Vannevar Bush, a prolific inventor and sometime advisor to President Roosevelt during WWII. In “As We May Think,” first published in The Atlantic in 1945, Bush proposed a purely hypothetical machine called the Memex: a kind of souped-up microfilm reader that has since become one of the platonic objects of the networked age. The Memex would allow its user to search across a large body of documents stored on film, then create associations—“links”—between them.
Like Otlet and the others before him, Bush recognized the urgent problem of information overload. “The investigator is staggered by the findings and conclusions of thousands of other workers,” he wrote, “conclusions which he cannot find time to grasp, much less to remember, as they appear.” Unlike Otlet, however, Bush saw no need for an army of indexers to keep track of the world’s information. He pointed out what he called “the artificiality of systems of indexing.”3
Bush argued that the human mind operates “by association,” not indexing. And so he proposed a system that would not impose any particular classification system, but would instead allow the user to create “associative trails” that would ultimately be made visible to other users. The essay proved wildly popular, especially after it was reprinted in Life magazine. That version of the essay found its way into the hands of a young Navy officer named Douglas Engelbart, then stationed in the Philippines, who found Bush’s vision so inspiring that he chose to devote much of the rest of his life to realizing it. Engelbart eventually landed a position at the Stanford Research Institute, where he attracted the attention of J.C.R. Licklider, professor at the Massachucetts Institute of Technology and then-new head of the Defense Department’s Advanced Research Projects Agency (ARPA, later renamed DARPA).
Engelbart worked in the 1960s San Francisco Bay Area, where an anti-institutionalist counterculture was then reaching its zenith (at one point he even experimented with LSD). The culture stood in stark contrast to the orderly, institutional tendencies of Otlet and Wells. Where Europeans were turning to their institutions in a time of crisis, many Americans were growing up in a value system that emphasized individualism and personal liberation. It was in this milieu that Licklider, Engelbart, and others began laying the foundations for the web we know today.
With Licklider’s support, Engelbart began work on a proto-hypertext tool that eventually came to be known as the oN-Line System. In 1968, he gave a demonstration of the system at the Herbst Theater in San Francisco, an event that has since gone down in computer history lore as The Mother of All Demos. Engelbart presented a startlingly far-sighted concept, complete with a word processor, a method for creating hyperlinks between documents, and live video conferencing, all operated by a keyboard and a rudimentary mouse (another Engelbart invention).
Where Otlet and Wells envisioned publicly funded, trans-national organizations, we now have an oligarchy of public corporations.
The 1960s novelist and Merry Prankster Ken Kesey later dubbed the system “the next thing after acid.” By the early 1970s, a “People’s Computer Center” had appeared in Menlo Park, California, providing access to rudimentary computer tools. Personal liberation, empowerment, and revolutionary rhetoric—all deeply American traits—shaped the attitudes of many early personal computer hobbyists, and have persisted ever since in the cultural fabric of the modern technology industry.4
The utopianism of that era found a particularly colorful expression in the work of Ted Nelson, a decidedly unconventional computing entrepreneur who promoted his own alternative vision of hypertext (a word he coined in 1963). A former filmmaker turned Harvard sociology student, Nelson developed a fascination with computers in the 1960s that led him to self-publish a series of visionary, over-the-top manifestos like Computer Lib and Dream Machines. These presented startlingly original concepts, with names like “Thinkertoys,” “Indexing Vortexes,” and “Window Sandwiches,” that pointed the way toward a radically personalized form of networked computing.
In his masterwork Literary Machines, published in 1981, Nelson proposed something called Xanadu. Taking its name from Samuel Taylor Coleridge’s opium-fueled depiction of Kublai Khan’s “pleasure dome,” Xanadu was a “universal data structure to which all other data structures will be mapped,” enabling millions of users to create and share their original written and graphical material.5 Though Nelson never realized his ambitions for Xanadu, it would provide direct inspiration for Tim Berners-Lee’s eventual creation of the World Wide Web.
Like many of his kindred spirits from the 1960s, Nelson took a strong dislike to centrally managed systems. “From earliest youth I was suspicious of categories and hierarchies,” he wrote. He was suspicious, too, of large institutions, and especially the university system, which “imbues in everyone the attitude that the world is divided into ‘subjects’; that these subjects are well-defined and well-understood; and that there are ‘basics,’ that is, a hierarchy of understandings.” The explosive growth of the web that would come 30 years later would have the unmistakable stamp of Nelson’s democratic computing ideal.

Today’s web seems to exist in a state of perpetual discord. There is a constant publishing and unpublishing, amid which we sometimes seem to be teetering on the brink of mass cultural amnesia. The lack of intellectual property controls has created massive—and avoidable—disruption for authors, musicians, and other members of the creative trades (although it’s worth noting that Nelson’s Xanadu proposed solutions for intellectual property concerns). The lack of stable identity management controls has ushered in the age of spam, phishing, and all manner of malware.
As a result, most of us rely on for-profit companies to make the web safe, useful, and usable. Today, Google and a handful of other major Internet corporations like Facebook, Twitter, and Amazon fulfill much the same role that Otlet envisioned for the Mundaneum—channeling the world’s intellectual output. Google freely excludes sites from its index for reasons that it is under no obligation to disclose—the secrets of the Googlebot are Delphic mysteries known only to its inner circle of engineers. An increasing number of web users rely on keyword searching and timelines, like Facebook’s, as their primary interfaces. Where Otlet and Wells envisioned publicly funded, trans-national organizations, we now have an oligarchy of public corporations.
While the web may be flat and open in both the public imagination and in the founding rhetoric of the World Wide Web Consortium, a truly flat web may have been just as much of an unreachable utopia as Otlet’s universal bibliography. More than a century after Otlet began work on his Mundaneum, the Consortium has begun to consider a new hierarchy that is remarkably Otlet-like in spirit. In May 2001, Tim Berners-Lee, the Consortium’s director, published a paper in Scientific American, along with two co-authors, proposing a so-called “web of data,” called the Semantic Web. The Semantic Web uses metadata, marked-up descriptions of content that follow a consistent set of rules (something like a library classification scheme). By allowing for the consistent use of ontologies, or standardized definitions of topics, content types, and relationships, the Semantic Web promises to make it easier to combine data from disparate sources.6 The Semantic Web uses a data model known as the Resource Description Framework (RDF) to encode subject-predicate-object relationships—in much the same way that Otlet’s Universal Decimal Classificiation used auxiliary tables to allow for the encoding of links between topics, as the historian of science Charles van den Heuvel has pointed out.
Just as Otlet’s ideas of centralized hierarchy encountered stiff opposition in his day, so too has the Semantic Web. Some have argued that the Semantic Web amounts to a betrayal of the principles that made the web successful in the first place. In a widely circulated 2005 essay, “Ontologies are Overrated,” technology pundit Clay Shirky argued that the Semantic Web was doomed to failure. “The more you push in the direction of scale, spread, fluidity, flexibility,” he wrote, “the harder it becomes to handle the expense of starting a cataloging system and the hassle of maintaining it, to say nothing of the amount of force you have to get to exert over users to get them to drop their own world view in favor of yours.” Shirky’s solution? Crowdsourcing. “The only group that can categorize everything,” he wrote, “is everybody.”7
Web pundit David Weinberger has also given eloquent voice to the anti-hierarchical ethos of the web, arguing that we “have to get rid of the idea that there’s a best way of organizing the world.” Rather than rely on institutional controls, he believes that the web’s messiness is an inherent virtue. “Filter on the way out, not on the way in,” he writes, predicting the emergence of what he calls a “third order” of knowledge, one not constrained by the physical limitations of paper, nor encumbered by layers of institutional gatekeepers.8
Shirky and Weinberger’s critiques point toward important practical challenges that are not easily solved. The question of who might “own” the Semantic Web is a thorny problem. Protocols and standards need an administrative infrastructure to be sustained—as Otlet learned through bitter experience. But there may be a third way. A burgeoning “Linked Data movement” is exploring how to automate the classification process by having computers crawl the web and create machine-generated ontologies, rather than relying on the manual curation of experts. The army of catalogers that Otlet and Wells envisioned may never materialize, but they may not need to: An army of searchbots and algorithms may just do the job instead.
Should the web remain free, flat, and open? Or would a more controlled and curated environment lead, paradoxically, to greater intellectual freedom? These questions can only be completely understood in a historical context, as the latest installment in centuries-old debates about hierarchy and access, efficiency and freedom, institutions and the individual. While it’s easy to give in to the temptations of historical exceptionalism and view today’s web as the pinnacle of humanity’s inexorable march towards liberation, variations on this dialogue have been swirling since before the dawn of the industrial revolution. At 25 years old, the web has plenty of growing up to do.
Alex Wright is the author of Cataloging the World: Paul Otlet and the Birth of the Information Age.
References
1. Borges, J.L. The library of babel. https://archive.org/stream/TheLibraryOfBabel/babel_djvu.txt (1941).
2. Wells, H.G. Today’s distress and horrors basically intellectual: Wells. Science News Letter 32, 229 (1937).
3. Bush, V. As We May Think. The Atlantic Monthly 176, 641–649 (1945).
4. Markoff, J. What the Dormouse Said: How the Sixties Counterculture Shaped the Personal Computer Industry Penguin Books, New York, NY (2006).
5. Nelson, T.H. Literary Machines Mindful Press, Sausolito, CA (1993).
6. Berners-Lee, T., Hendler, J., & Lassila, O. The semantic web. Scientific American 284, 29-37 (2001).
7.Shirky, C. Ontology Is Overrated. http://www.shirky.com/writings/ontology_overrated.html
8. Weinberger, D. Everything Is Miscellaneous: The Power of the New Digital Disorder Times Books, New York, NY (2007).









