The Things That Fuel Our Dreams
“What dreams may come” depends on your personality

Trump’s War on Science Continues
As sacked National Science Board members and lawmakers speak out, US research preeminence further dims on the international stage

Why Cooperation Falls Apart Over Time
It’s a question of motivation

What Happens When Giants Disappear from Ecosystems?
Big animals leave big holes in the food web

The Science of Spooky Sounds
A conversation with a “pseudoscience” researcher about how infrasound could be linked to ghosts

Latest Stories

These Bees Change Color with the Weather
But the biological significance of their shifts is a mystery

From our latest print issue
See more


Get the Nautilus newsletter
Cutting-edge science, unraveled by the brightest living thinkers.
Astronomy
See more Astronomy(Almost) A Eulogy for Voyager
The robotic space probe is 15 billion miles away and is nearing the end of its life in the distant cosmos

The Origins of Uranus’ Distant Rings Hint at a Hidden Moon
Astronomers are circling the answers

The Peace That an Eclipse Brings
The total solar eclipse in 2024 hushed the Earth by striking awe in the humans in its path

History
See more HistoryRome Was Built Today
Celebrating the scientific and technical contributions of Rome on the mythical birthday of the eternal city

The Birth of Genius
Leonardo da Vinci, polymath and victim of the vagaries of science funding, was born on this day

The Bra-and-Girdle Maker That Fashioned the Impossible for NASA
Crafting a spacesuit demanded perfection from seamstresses to gluers to engineers — every stitch could mean life or death

Psychology
See more PsychologyThe Problem with Psychedelic Research
A conversation with a psychedelics researcher about a fundamental flaw in how we test these mind-bending drugs



Get unlimited, ad-free Nautilus. Become a member today.
Environment
See more Environment
Earth Day Started with an Oil Spill
The day of environmental action and protest has grown and evolved over the past 56 years

Cocaine Fish: How Salmon Behave When Amped Up on Coke
The effects of cocaine pollution in the world’s waterways

Zoology
See more Zoology

Philosophy
See more PhilosophyThe Bad Seed and the Problem of Blame
A conversation with behavioral geneticist Kathryn Paige Harden about the heritability of vice

A Light in the Dark: Finding the Good in the Natural World
Is it absurd to think that science can inform our values?

How ‘Tiny Shortcuts’ Are Poisoning Science
Seemingly harmless data tweaks are undermining the integrity of the entire field. We must define the problem to prevent it

When “Extinct” Volcanoes Reawaken
They’re filled with a lot more fury than their millennia-long slumber would suggest

Read more
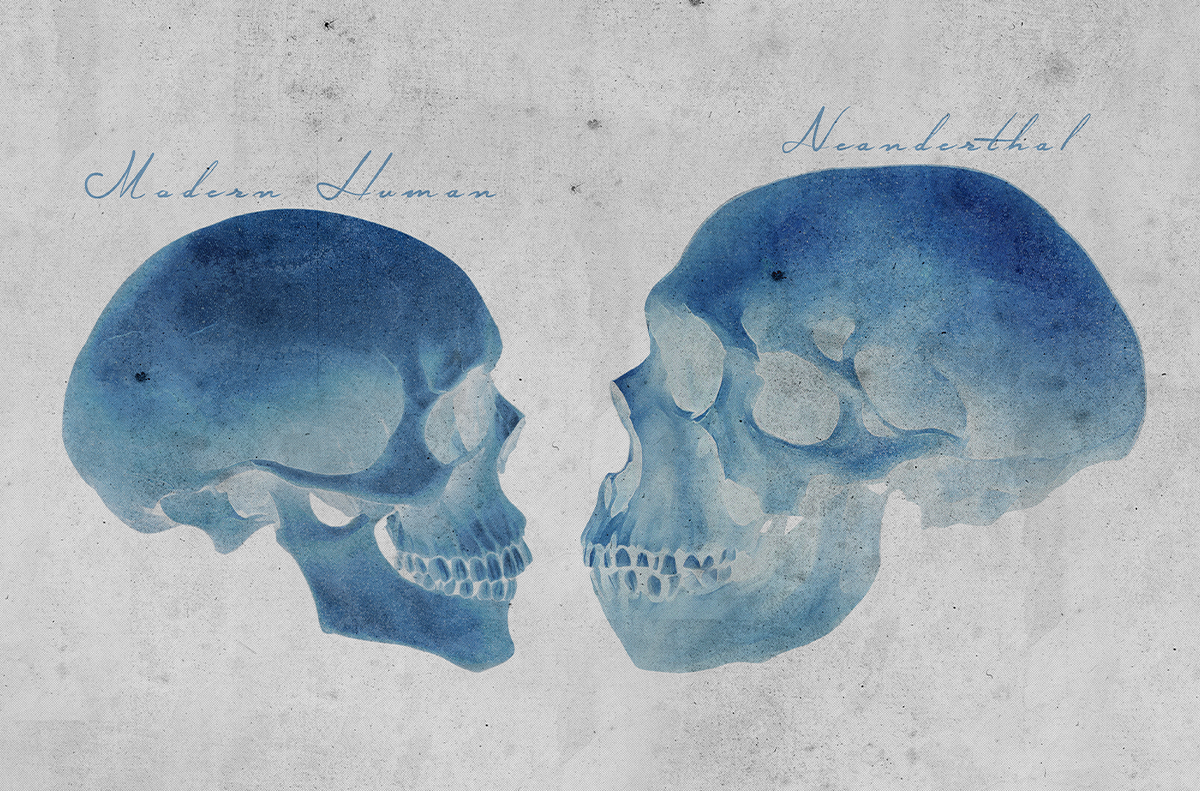
See all postsWhat Mummies Read Before a Long Nap
Archaeologists have recovered a scrap of the Iliad in the belly of an interred Egyptian

The Australian Rocks That House the Oldest Life-Forms on Earth
Never underestimate the power of an old pile of rocks


The Nautilus Reading List of Science Biographies
These beautifully composed books usher you into the life and times of influential scientists

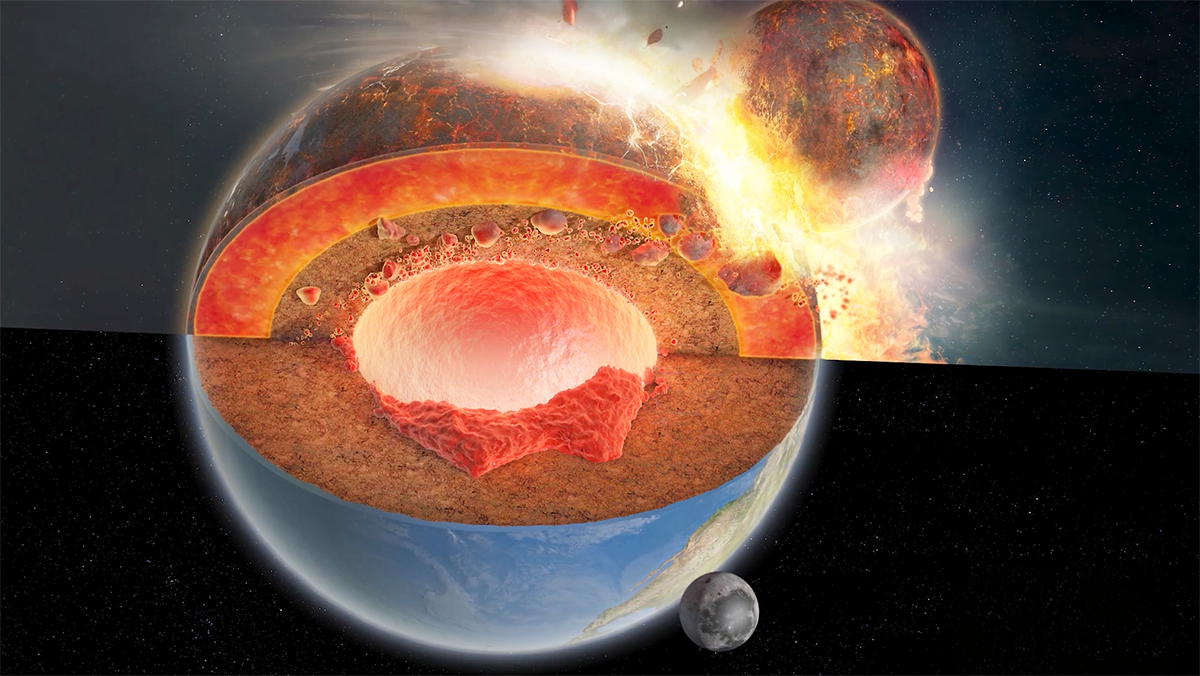
The Mystery of the Giant Blobs at the Center of the Earth
Are they remnants of primordial Earth or extraterrestrial in origin?
Mars Curiosity Rover Makes a Big Find on the Red Planet
The little robotic chemist that could


Mushrooms Stole a Trick From Bacteria. It Could Help Us Control the Weather
Can purloined genes make it rain?
