



Can AI teach itself the laws of physics? Will classical computers soon be replaced by deep neural networks? Sure looks like it, if you’ve been following the news, which lately has been filled with headlines like, “A neural net solves the three-body problem 100 million times faster: Machine learning provides an entirely new way to tackle one of the classic problems of applied mathematics,” and “Who needs Copernicus if you have machine learning?”. The latter was described by another journalist, in an article called “AI Teaches Itself Laws of Physics,” as a “monumental moment in both AI and physics,” which “could be critical in solving quantum mechanics problems.”
The trouble is, the authors have given no compelling reason to think that they could actually do this.
None of these claims is even close to being true. All derive from just two recent studies that use machine learning to explore different aspects of planetary motion. Both papers represent interesting attempts to do new things, but neither warrant the excitement. The exaggerated claims made in both papers, and the resulting hype surrounding these, are symptoms of a tendency among science journalists—and sometimes scientists themselves—to overstate the significance of new advances in AI and machine learning.
As always, when one sees large claims made for an AI system, the first question to ask is, “What does the system actually do?”
The Three-Body Problem
The three-body problem is the problem of predicting how three objects—typically planets or stars—move over time under mutual gravitational force. If there are only two bodies, then, as Newton proved, the behavior is simple: Each of the objects moves along a circle, an ellipse, or a hyperbola. But, as Newton and his successors also determined, when there are three or more bodies involved, the behaviors can become very strange and complex. There is no simple mathematical formula; and accurate prediction over extended periods of time becomes very difficult. Finding good ways to calculate solutions to the three-body problem and the n-body problem (the same problem, with more objects) has been a major challenge for computational physics for 300 years. The slew of “AI that solves the three-body problem” articles were based on an article in arXiv entitled “Newton vs The Machine: Solving The Chaotic Three-Body Problem Using Deep Neural Networks.”
As is often the case, the technical article is less over the top than the popular ones, but, for a technical scientific article, this one is still pretty ambitious. It ends with the prediction that techniques developed for a narrow case should extend both to the general three-body problem and then ultimately to the four- and five-body problems and other chaotic systems, which could conceivably constitute a genuine revolution.
The trouble is, the authors have given no compelling reason to think that they could actually do this. In fact, they haven’t even engaged in the full breadth of the existing three-body problem. Instead, they focused only on a special case of the three-body problem, involving three particles of equal mass starting from specified positions with zero velocity.
Even here, they are entirely dependent on a conventional physics engine or simulator—which is to say no AI, no machine learning, just traditional numerical solution of the differential equations of motion—to generate the trajectories of motion over time from 10,000 different starting positions.
The media enthusiasm is sending the wrong impression, making it sound like any old problem can be solved with a neural network.
They then used this classically-derived database as input, to train the neural network. In testing the neural network on new examples, whose true solution was also calculated by the simulator, they found that the neural network could predict the later positions of the particles with reasonable accuracy, orders of magnitude faster than the conventional simulator.
In essence, what they were doing was to use the neural network as a new tool for interpolating from known values derived using an external, classical system. The neural network may be better at interpolation with a smooth space of values than other techniques, but most of the work comes from the external prior system doing the work. And, crucially, they haven’t shown that the same sort of interpolation would actually work in the more complex physics of the actual world, even for simple cases (particles of different masses), let alone in situations with more bodies than just three.
Meanwhile, in technical terms, even within the three-body problem, the class of problems they have solved has is an easy subset viz. two degrees of freedom—that is, a problem instance is determined by two numerical parameters—whereas the general three-body problem has 10 degrees of freedom. In their limited version of the problem, the only choice you have in formulating a problem that fundamentally changes the behavior is where to place the third object relative to the first two. In the full problem, which they didn’t attempt, you can additionally choose the masses and initial velocities of the second and third objects; and each of these choices can radically change how the system evolves over time.
And we know that the complexity of this kind of problem tends to increase exponentially with the number of degrees of freedom. So the problem they have solved is not five times easier than the general problem, it is vastly easier. And the problem gets rapidly worse as you add more points: the four-body problem has 17 degrees of freedom, the five-body has 24, the n-body has 7n-11.
Second, if you only have to worry about two dimensions, then calculating 10,000 data points gives pretty good coverage. If, let’s say, you want to map out the shape of a mountain, and you measure the elevation at 10,000 points—essentially, every point on a 100 x 100 grid—then you can estimate the elevation at any point in between pretty reliably. Things get much more complex as the number of dimensions increases, and the possibility of smooth interpolation working diminishes.
Third, the scientists failed to wrestle with the 800-pound chaotic butterfly in the room: the high degree of dependence on starting conditions. Two slightly different starting conditions can lead to radically different outcomes. This is not a limitation of the algorithm that you used to make the prediction; it is an inherent characteristic of the problem. Therefore, claiming that a machine learning system has learned to predict a chaotic system over the long term is like saying that it has learned to predict the behavior of a random process, like thermal noise or radioactive decay. It simply can’t be done, regardless of the algorithm. (Kudos to Caroline Delbert at Popular Mechanics for noticing this; most journalists missed it.)
Finally, even the comparison with a conventional simulator was flawed. Jonathan Goodman, of the math department at New York University, an expert on these kinds of dynamical systems, assures us that modern adaptive methods can compute these trajectories much faster than the timings quoted in the paper; the conventional simulator was a straw model.
Copernicus
The situation with the Copernicus project is no better.
Here a different set of authors, in work to be published in Physical Review Letters, constructed a neural network designed to take as input numerical data from a physical process and extract the key parameters that determine the behavior of the process. They described four experiments involving simple physical systems of different kinds, in which their neural network succeeds as they had hoped.
The supposed rediscovery of the Copernican system from astronomical observation is what caused excitement in the popular press.
The trouble is that it is entirely misleading to say that their neural network infers that “the Earth and Mars revolve about the sun.” The neural network doesn’t actually understand that anything is revolving around anything, in a geometric sense; it has no sense of geometry and no idea what it would mean to revolve. All the neural network does is to extract the two numerical parameters involved; it has no idea that these represent angles from some fixed central point. As far as the network is concerned, these could be time-varying masses, or electric charges, or angles from two different central points. Correlations between data sources were extracted, but the system made no inferences about how those data sources related to the world; it is the human scientists who identify these as the angles of the Earth and Mars as measured from the sun, and who abstract the facts that such parameters are best interpreted as orbits. All of the real work of Copernicus’ actual discovery is done in advance; the system was a calculator, not a discoverer.
Further, in the synthetic data the authors generated, the Earth and Mars move in constant-velocity circular orbits in the same plane. In the real solar system, things are notably trickier: The plane of Mars’ orbit is tilted at 1.8o to the plane of the Earth’s orbit (the ecliptic). In consequence, the apparent position of Mars against the fixed stars does not just move on an east-west circle, as it would if the two orbits were co-planar; it also moves back and forth on a north-south arc about 4o long. Viewed over a period of years, the position of Mars does not stay in a simple circular path in the sky; it lies in a strip that is 4o wide at its widest. Copernicus’ real challenge (solved long before modern computers, and without Big Data) was vastly more complex than what the network had to deal with.
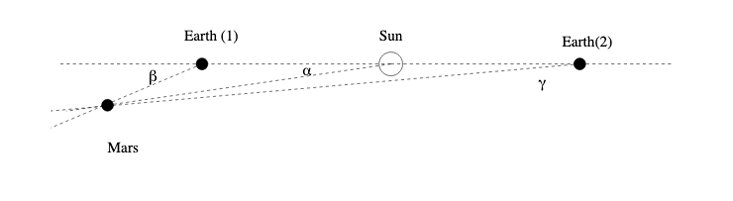
Four degrees may sound small, but by the standards of astronomical observations, it is huge. By way of comparison, Orion’s belt is only 2.7o wide. Measurements in Ptolemy’s Almagest are mostly accurate to within about 1/10 of a degree.
Accordingly, both the Ptolemaic and the Copernican models of the solar system must have mechanisms to account for this transverse motion of Mars and the other planets. The Copernican model is therefore necessarily much more complicated than the simple model, that was produced (in a sense) by the neural network, in which the Earth and Mars revolve around the sun in circular orbits. In fact, the Copernican model included 48 epicycles, more than the Ptolemaic model, though it was simpler in other respects. The network system doesn’t even engage in the transverse movement.
Buoyed by their supposed success in duplicating Copernicus’ accomplishment, the authors and journalists look forward to the days when this kind of machine learning technology can make radical advances in theoretical physics. An article in Nature News even enthused, “A neural network that teaches itself the laws of physics could help to solve quantum-mechanics mysteries.”
This is pure fantasy. In the examples in this experiment, the relation between the data observed and the parameters extracted is fairly straightforward. By contrast, in most of the experimental evidence for quantum theories, the relation between the observations and underlying theories is extraordinarily indirect and subtle and requires extremely ingenious theorizing to reveal; detecting correlations as these neural network systems does not even scratch the surface of what would be required.
Why It Matters
The flaws in these particular studies are not huge in themselves, but the way they have been reported is symptomatic of a problem that is in fact serious. Such overblown reports lend false credence to the idea—most notoriously promoted in Chris Anderson’s 2008 infamous article, “The End of Theory: The Data Deluge Makes the Scientific Method Obsolete,” and increasingly part of the general zeitgeist—that AI generally and deep learning theory will soon replace all other approaches to computation or even to knowledge, when nothing of the sort has been established. The media enthusiasm for deep learning is sending the wrong impression, making it sound like any old problem can be solved with a massive neural network and the right data set, without attention to the fundamentals in that domain.
The truth is that many of the hard, open problems in the world require a great deal of expertise in particular domains. In the sort of problems in these two papers, it means if someone wants to make a useful contribution to the solution of the three-body problem or similar problems, one has to spend serious time studying the sophisticated science of differential equations, numerical computation, and dynamical systems. In the domain of natural language understanding, it might similar mean incorporating a great deal of work in linguistics and psycholinguistics, rather than gathering just a large data set and large assembly of sophisticated computers.
The widespread misimpression that data + neural networks is a universal formula has real consequences: in what scientists choose to research, in what companies and governments choose to fund, in what journals and conferences choose to accept for publication, in what students choose to study, and in what universities choose to teach. The reality is that neural networks, in anything like their current form, cannot replace the sophisticated tools of scientific analysis, developed over centuries, and have not thus far duplicated the great scientific accomplishments of the past—let alone improved upon them. They should be seen as tools that supplement existing techniques, not foundational revisions to how we do science.
Acknowledgements
Thanks to Jonathan Goodman for very useful information about the three-body problem study, and to him and Kyle Cranmer for helpful feedback on a draft.
Gary Marcus and Ernie Davis are co-authors of Rebooting AI: Building Artificial Intelligence We Can Trust, and of numerous scientific and popular articles on cognitive psychology and artificial intelligence.
Gary Marcus is a scientist, best-selling author, and entrepreneur. He is the founder and CEO of Robust.AI, and was the founder and CEO of Geometric Intelligence, a machine learning company acquired by Uber in 2016. In addition to Rebooting AI, he is the author of five books, including The Algebraic Mind Kluge, The Birth of the Mind, and The New York Times best seller Guitar Zero.
Ernie Davis is a professor of computer science at the Courant Institute of Mathematical Sciences, New York University. He is one of the world’s leading experts on common sense reasoning for artificial intelligence. He is the author of four books, including the textbooks Representations of Commonsense Knowledge and Linear Algebra and Probability for Computer Science Applications, and Verses for the Information Age, a collection of light verse. With his late father Philip J. Davis, he edited Mathematics, Substance and Surmise: Views on the Meaning and Ontology of Mathematics.
Lead image: metamorworks / Shutterstock









