



Back in the 1970s, you might open up a box of cereal one morning and out would fall a cardboard disk. It was a code wheel, which allowed preteen cryptographers to ply their trade. The wheel had two disks of unequal size, joined at the center, so that you could turn each of them on the common axis. Letters ringed the outer wheel, and the inner wheel was marked with an arrow. If you lined the arrow up with a letter, a window in the inner wheel revealed a different letter. You could write out a message in those coded letters that would look like gibberish to outsiders (most importantly, to your parents). The only way to understand the message was to decipher it with the help of another code wheel from another box of cereal—provided, of course, it was the same brand.
The image of that code wheel always comes back to mind whenever I page through a biology textbook and see this:
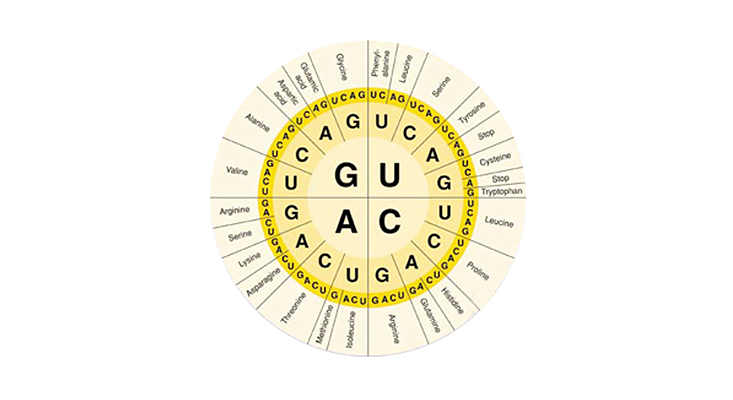
It is a code wheel of sorts. But it’s not for encrypting messages like, Meet me in the backyard with the Micronauts. It’s a code wheel that exists in our own bodies, in every one of our 30 trillion cells1, enabling them to translate the recipes stored in our DNA into the stuff we are made of. You can find the same code wheel in pretty much identical form in every species on Earth. It is, when you get down to it, the code of life.
This genetic code is different from an organism’s specific genetic sequence—a much more familiar concept. Take the genome of the gorilla. It is stored in the ape’s DNA, consisting of a series of chemical units called bases, each one like a letter in a book. In the case of the gorilla, that book is 3.04 billion letters long, comprising 21,000 genes.
To translate the gorilla’s genes into the corresponding proteins2 that build and do almost everything in the gorilla’s body, its cells use a set of rules: the genetic code. A genetic sequence is a book, but without the code, it’s meaningless—like hieroglyphics without the Rosetta stone.
Scientists cracked the genetic code in the 1960s. It was one of modern biology’s great triumphs, on par with the discovery of DNA’s double-helix structure. It enabled scientists to engineer organisms with new genes, opening the way for our age of biotechnology.
Five decades later, the genetic code still enchants scientists. They continue to debate how it evolved, and why there aren’t lots of different codes. And as they come to better understand the history of the genetic code, scientists are creating a future for it. They are re-coding cells to build new kinds of proteins never seen in nature, which could be the basis for new kinds of medicine.
This research goes beyond the advances in biotechnology we see routinely in the news—reading genes, for example, or fine-tuning the proteins they encode. It changes the biological meaning of DNA. By re-coding life, scientists may eventually engineer new kinds of organisms fundamentally different from anything that’s existed on Earth over the past 4 billion years—a kind of alien life created in the lab.
A Mysterious Mess
When Francis Crick and James Watson published the structure of DNA in 1953, they solved many mysteries about life in one fell swoop. Earlier generations of scientists had puzzled over the chemistry that could make heredity possible. DNA provided an elegantly simple answer. It was made of two backbones, along which were arrayed a series of bases. DNA needed only four bases—abbreviated as A, C, G, and T—to produce all of life’s diversity. One combination of bases gives you a gorilla. Another, a sunflower.
But despite this triumph, Crick and Watson had no idea how a cell could use its DNA to build proteins. What made this mystery particularly baffling was that proteins are based on a different kind of chemistry from genes. While DNA is composed of bases, proteins are made from 20 different Lego-like compounds called amino acids that snap together to form long, flexible chains.
When the Russian-born scientist George Gamow read Watson and Crick’s paper, he immediately recognized that this puzzle was a matter of cryptography. DNA contained messages composed from a four-letter alphabet. Proteins were sequences, too, but they were composed from a different alphabet with 20 letters. Somehow, that four-digit system could store information for making all the proteins in our bodies—from our muscles to our neurotransmitters to our digestive enzymes. “Thus the question arises about the way in which four-digital numbers can be translated into such ‘words,’ ” Gamow later wrote.
To answer that question, Gamow approached it much as British cryptographers had when they cracked Nazi Germany’s Enigma machine a decade earlier. Rather than running a biology experiment, Gamow relied on logic. He proposed—with no hard evidence—that proteins formed when amino acids dropped into holes in DNA molecules. Here’s how Gamow pictured this (the bases, wrapping around the double helix of DNA, are shown as circles. The diamonds are the holes for amino acids):
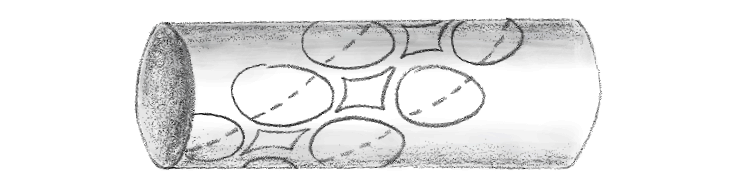
Gamow proposed that only one type of amino acid could fit between a given assemblage of bases. He calculated that there were 20 different diamonds, which would perfectly fit the 20 different amino acids.
Surely that couldn’t be a coincidence, Gamow suggested.
While Gamow’s answer was elegantly clean, it was completely wrong. The right answer eventually turned out to be almost clumsily baroque: Cells make proteins by first making a single-stranded copy of a gene, called messenger RNA. A molecular factory called a ribosome grabs the messenger RNA and reads its sequence, plucking amino acids floating around the cell to build the protein specified by the DNA.
The ribosome reads three bases at a time to pick out each new amino acid, and each of these triplets is called a codon.
Here again is the wheel that illustrates the genetic code. It represents all the codons in the genetic code, starting from the center and moving outward. GUA, for example, encodes valine.
The biggest surprise about the genetic code is that more than one codon can encode the same amino acid. Not only does GUA encode valine; so do GUC, GUG, and GUU3. Other amino acids are encoded by three codons, others by two. Only a few amino acids are encoded by a single codon. It’s a far cry from the sleek, one-to-one code Gamow dreamed of. The real genetic code seems like a spectacular mess.
If I had gotten a cereal-box code wheel that worked this way, I’d have written to General Foods for a refund.
One Code to Rule Them All
To crack the genetic code, scientists started out studying the gut bacteria E. coli. They chose that particular microbe because generations of scientists before them had studied it, assembling a massive kit of tools for dissecting its biochemistry. Once they finished working out E. coli’s genetic code, they began examining other species. In case after case, the scientists found the exact same quirky system.
Ever since the discovery of the genetic code, scientists have wondered how we ended up with this universal, sloppy arrangement. Some researchers have argued what seems like sloppiness is actually ruggedness—that natural selection favored the genetic code because it was more resilient than earlier versions. By using more than one codon for an amino acid, an organism can defend itself against harmful mutations.
When the Russian-born scientist George Gamow read Watson and Crick’s paper, he immediately recognized that this puzzle was a matter of cryptography.
If GUC mutates to GUU, for example, our cells don’t switch to a different amino acid and thus create a defective protein. It picks valine in either case. In one study, researchers created a vast number of random genetic codes and measured how well they withstood mutations. The real genetic code ranked in the top 0.000001 percent of all possible codes.
Other scientists disagree with this literal one-in-a-million view of the genetic code, saying there may be nothing special at all about it. In 1968, Crick proposed that the genetic code arose through a process he lyrically dubbed a “frozen accident.”
Crick argued that the earliest forms of life had primitive, sloppy genetic codes. Cells would frequently make mistakes as they deciphered codons, grabbing a different amino acid. Because their proteins were small and simple, these early life-forms could make do with defective ones.
Over time, microbes emerged with more precise codes. The chances that a cell would misread a particular codon fell. They also started using many more amino acids, allowing them to build more complex and useful proteins.
Eventually, Crick argued, the cells got so complex that tinkering with their genetic code became very risky: One mutation might make a cell churn out defective versions of hundreds of different proteins, leading to catastrophic failure. The evolution of the genetic code screeched to a halt.
Other researchers, like Nigel Goldenfeld of the University of Illinois, see the code more like a language that made it possible for different species to use the same genes, a biological lingua franca. Microbes sometimes pick up genes from other species, and sometimes the genes prove to be a huge boon. Inside our bodies, for example, antibiotic-resistant bacteria can donate their genes for fending off drugs to vulnerable species. But the only way that borrowed genes can provide a benefit is if a cell can decode them.
Over millions of years, Goldenfeld argues, life’s many genetic codes gravitated toward each other, enabling a worldwide commerce in DNA, until a single code was left.
Code Cat and Mouse
Decades after the discovery of the universal genetic code, scientists found out that it wasn’t exactly universal. In 1992, researchers discovered an exception to the genetic code’s rules. It was an exception lurking in our own cells.
The vast majority of human DNA is stored within the cell in a sac called the nucleus, but a few scraps of DNA lurk inside small, fuel-producing structures called mitochondria. Mitochondria are like miniature cells inside our cells, decoding their own genes with their own ribosomes. (They most likely started out as miniature cells of their own, in fact—their ancestors were probably free-living bacteria that invaded our cells more than 2 billion years ago.)
While studying mitochondria, scientists stumbled across a surprising discovery: Their code did not quite match the code for DNA in the nucleus. Normally, for example, UGA gives a ribosome the order to stop making a protein and release it. In human mitochondria, UGA is no longer a “stop codon”: Here, it encodes the amino acid tryptophan.
Crick proposed that the genetic code arose through a process he lyrically dubbed a “frozen accident.”
Since that first discovery, researchers have found 34 cases of alternative genetic codes. Each case was the result of an evolutionary modification of the ancestral code. Ken Miller, a cell biologist at Brown University, likens these variations to dialects. “The differences in spelling and word meanings between the American, Canadian, and British dialects of English reflect a common origin. Exactly the same is true for the universal language of DNA.”
In almost every known alternate genetic code, one codon has been reassigned from one of the standard 20 amino acids to another. But a few species have expanded the code to include new amino acids not used by other life-forms. Certain microbes have switched one of their codons to an amino acid known as selenocysteine. Others have added pyrrolysine. Some species have added both of them to their repertoire.
These genetic dialects have created a puzzle for biologists. The species with alternative genetic codes are very distant relatives of one another—they reside on far-flung branches of the tree of life. That means that evolution has, over and over again, changed the genetic code.
In 2009, Edward Holmes, an evolutionary biologist then at Penn State University, and his colleagues discovered something else that these species had in common—something that might be a force that could drive the evolution of an alternative genetic code. When the researchers looked at all the species known at the time to have an alternative genetic code, there was no evidence that a virus could infect any of them.
Holmes and his colleagues proposed that escaping viruses is what drives some species to change their genetic code. While viruses can be exquisitely deadly to their hosts, they also depend on their hosts for their survival. Typically made up of nothing more than genes encased in a protein shell, viruses don’t have ribosomes or the other components required to make proteins or genes. To replicate, they invade a cell and trick it into reading out the virus’s genes.
In order to successfully infect a host, though, viruses have to use the same code as their host. If their code doesn’t match, a host cell will produce defective virus proteins, and the new viruses won’t be able to survive.
“The differences in spelling and word meanings between the American, Canadian, and British dialects of English reflect a common origin. Exactly the same is true for the universal language of DNA.”
When a deadly new virus epidemic breaks out, the viruses are likely to eradicate most of the hosts. A mutant host with an alternative genetic code may be more likely to survive, because the viruses can’t exploit them. They survive and rebuild the population. And from then on, the host species is immune to all viruses, thanks to their alternative genetic code.
Earlier this year, however, scientists at the University of Buffalo discovered the first virus that infects a species with an alternative genetic code. Its host is a species of yeast in which CUG has changed from coding one amino acid (leucine) to another (serine).
When the researchers looked closely at the virus’s DNA, they saw that the CUG codon is almost entirely missing. Once the yeast altered its code, it seems, the virus changed its own genetic messages so that they wouldn’t get garbled. By getting rid of CUG the virus eliminated the risk of producing faulty viruses. Evolving an alternative genetic code is a good way to evade viruses, but it may not guarantee immunity.
Some of the viruses may be able to catch up.
Life’s New Master Code Makers
The discovery of the genetic code in the 1960s permeates our everyday lives 50 years later. Once scientists realized that humans and E. coli used the same code to decipher their genes, they wondered if the microbe could make proteins from human DNA. Herbert Boyer and his colleagues figured out how to snip out a gene for insulin from human cells and insert it into the bacterium. Just as they’d hoped, the microbes began to churn out insulin. Today millions of people with diabetes inject themselves with insulin that was made by bacteria.
Scientists are becoming more and more adept at using the genetic code to produce valuable molecules. They can make goats produce spider silk in their milk. They can tweak genes to make new proteins, such as tailor-made antibodies designed to attack certain pathogens. All these feats are possible because of life’s lingua franca.
Yet the genetic code also puts limits on biotechnology’s creativity. It encodes only 20 amino acids. There are hundreds of other amino acids in nature (even some seen in interstellar space) that were never incorporated into life. What’s more, scientists can synthesize unnatural amino acids of practically infinite variety. If scientists could reprogram the genetic code to include these other amino acids, it would open up a universe of possibilities for how to control life.
The fact that nature has already tweaked the genetic code gave researchers the confidence to try to alter it some more. They carried out their first attempts in the early 2000s. In one such study in 2002, Peter Schultz, a chemist at the Scripps Research Institute, and his colleagues created proteins that are sensitive to light.
Scientists are becoming more and more adept at using the genetic code to produce valuable molecules. They can make goats produce spider silk in their milk.
Schultz and his colleagues managed this feat by joining an ordinary amino acid (phenylalanine) and a photosensitive compound called a benzophenone. A flash of UV light gives benzophenones a jolt of energy that lets them bond to a nearby protein.
Next they changed the molecules in the cell so that instead of reading UGA as a stop codon, they would instead code for the novel benzophenone-carrying amino acid. Schultz and his colleagues then added the genes to E. coli. They allowed the bacteria to make proteins, which they then harvested. When the researchers flashed UV rays at the proteins, some of them joined together, thanks to the bonds formed by their benzophenones. The bacteria had made molecules no organism had ever made before.
Schultz went on to help found a company called Ambryx based on such experiments, and in 2012, they inked a $303 million deal with pharmaceutical giant Merck to explore new ways to make drugs by altering the genetic code.
In one typical project, they’re trying to develop anti-cancer molecules that act like guided missiles against tumors. The researchers hope to improve an existing class of drugs made from proteins known as monoclonal antibodies. These antibodies can be engineered to attack only cells that have turned cancerous. Standard monoclonal antibodies stick to cancer cells and make them more conspicuous to immune cells, which can then kill them.
Ambryx researchers are investigating how to make these antibodies themselves do the dirty work. They are fashioning unnatural amino acids that carry toxins and engineering microbes that can build these toxin-carrying amino acids into the antibodies. Their hope is that once these unnatural antibodies attach to cancer cells, their toxins will immediately kill the cells.
For now, expanding the genetic code is only a promising technology, not a salvation. Merck does not have tanks full of E. coli churning out cancer drugs. No one knows how efficiently bacteria can make these unnatural proteins.
It’s possible that more radical changes to the genetic code could end up being more successful. Farren Isaacs, a biochemist at Yale, and his colleagues are running one such ambitious project. Instead of one new codon, they want to alter dozens. If they succeed, they may create organisms that build profoundly new proteins. Their re-coded microbes would be unlike anything alive today—and perhaps unlike anything that has ever existed on Earth.
Isaacs wants to take advantage of the tremendous redundancy of the genetic code. Instead of using four different codons for the amino acid arginine, he would like to rewrite an organism’s DNA so that it uses only one. That revision would free up three codons he could engineer to encode unnatural amino acids. With 44 redundant codons in the standard genetic code, this strategy could open up vast new biological possibilities.
In a study published earlier this month in Science, Isaacs and his colleagues took the first step on this path. They used new gene-editing tools to search for every instance in the E. coli genome of the stop codon comprising the sequence UAG: It turned out there were 314. Isaacs and his colleagues surgically replaced 314 UAGs with the sequence UAA, another stop codon. The bacteria did perfectly well without the redundant version.
This experiment marks the first time researchers have ever changed a codon across an organism’s entire genome. And it now leaves UAG free to encode a new amino acid, enabling scientists to add TAG codons to many different genes. If this method works, they might be able to do the same with other redundant codons, too.
Rewriting the genetic code this way might allow scientists to do more than just create new kinds of molecules. Today, biotechnology operations are beset by viruses, which kill the microbes scientists use to produce new molecules. Isaacs’s re-coded microbes might be made immune to viruses, which could no longer hijack their ribosomes.
A new genetic code might also make it possible to eliminate the risk that engineered microbes could escape from labs to wreak havoc. Scientists might be able to engineer the microbes to depend on unnatural amino acids for their survival. Should they escape the lab, they would find only natural amino acids and die. These altered species would, in other words, become slaves to our code, fundamentally divorced from the natural code used by the rest of the living things on our planet.
Today’s controversies over genetically modified food are fueled by the notion that we have suddenly started tampering with DNA in a dangerous way. In fact, we have been tinkering with DNA for thousands of years, ever since we started domesticating crops and livestock. The genes of a juicy cob of corn are quite different from those in its hard-seeded teosinte forerunners. Biotechnology has enabled us to move genes from one species to another with greater skill in recent decades, and scientists are even starting to edit individual bases of DNA to fine-tune genes.
But as weird as a microbe with a human insulin gene may seem, it still uses the ancient code that life has relied on for billions of years. We may now be on the verge of an entirely new era—one where we, not natural evolution, control the code of life.
Carl Zimmer is a columnist for The New York Times and the author of 12 books, including A Planet of Viruses.









